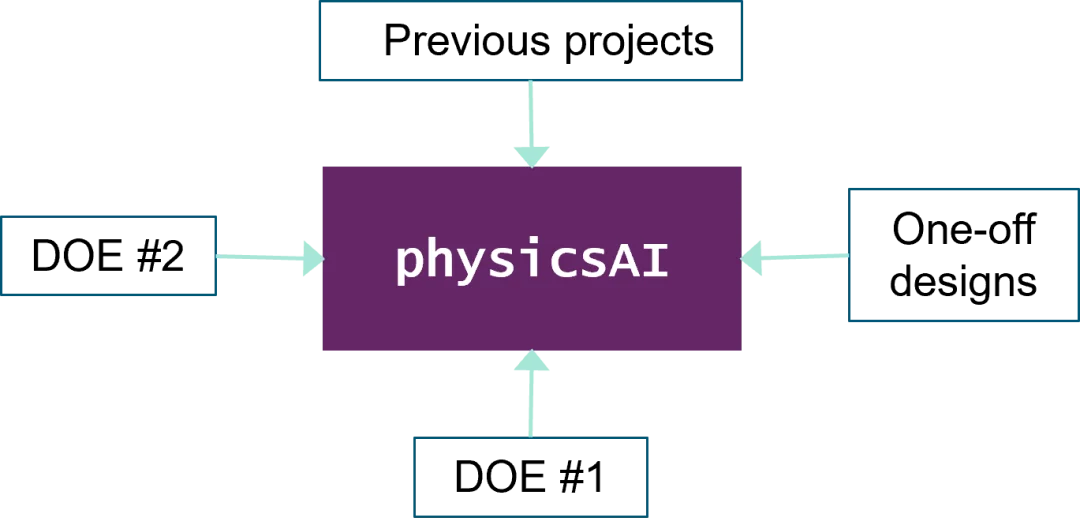
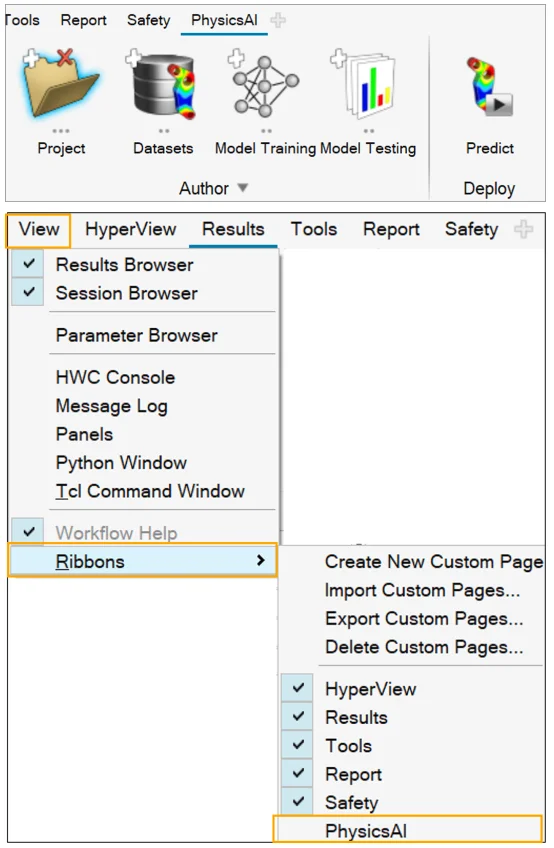
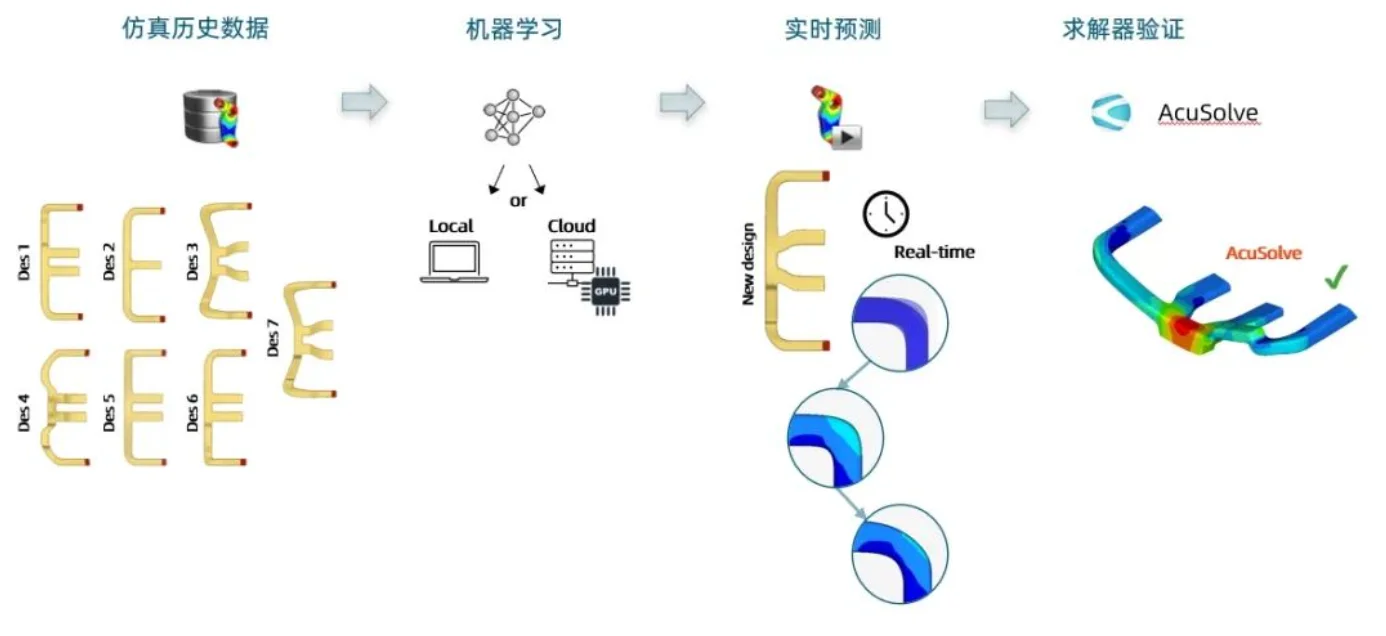
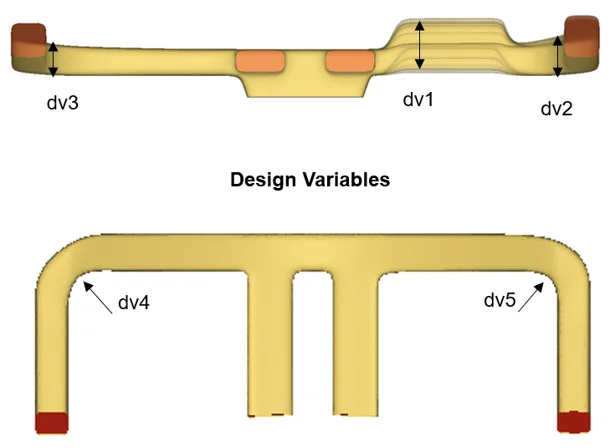
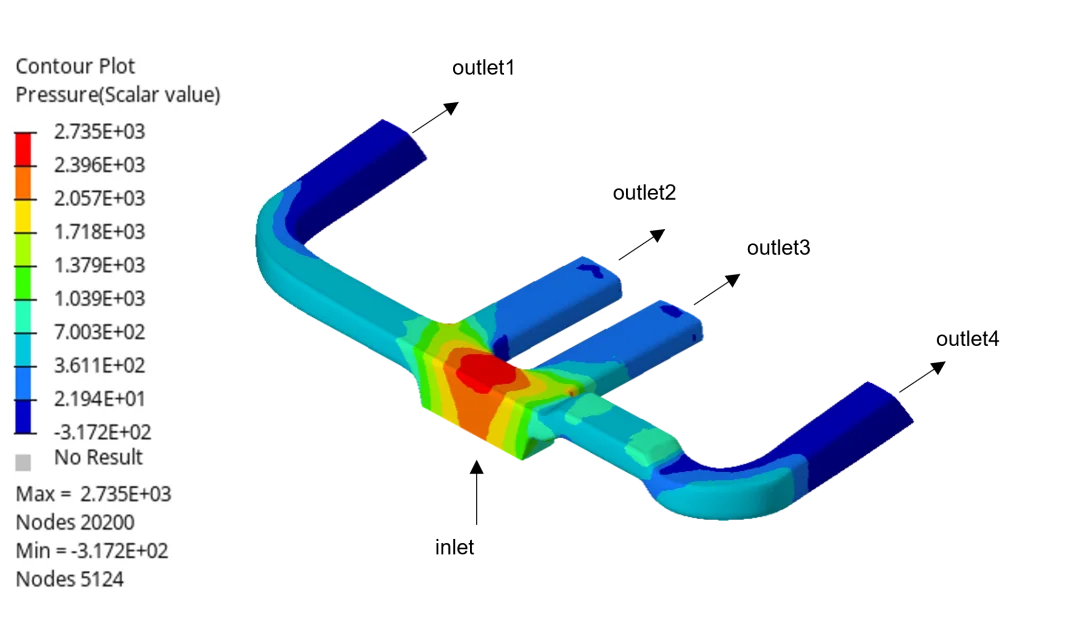
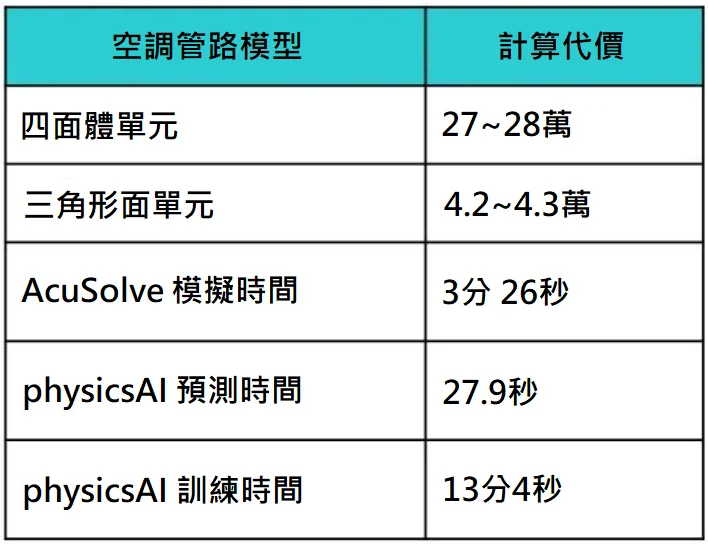
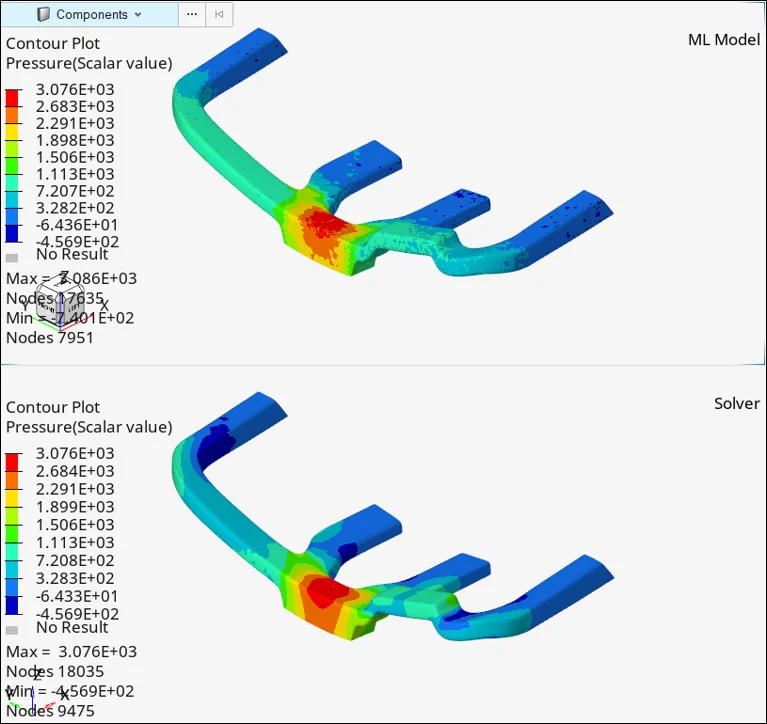
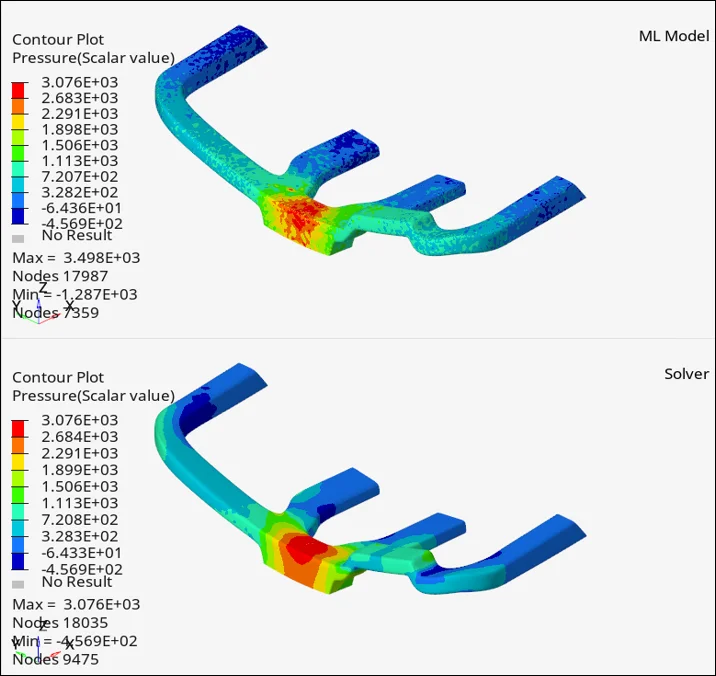
- 公司簡介
- 產品介紹
- 案例實績
-
技術中心
HyperWorks 新版亮點HyperWorks 最新版 / 所有版次【硬體規格需求】 【HyperWorks 2025.1 】新版 - 文章總覽 【Inspire Motion 2025.1】新版功能大躍進 【HyperMesh 2025】與【SimLab 2025】前處理新亮點解密 【Altair PhysicsAI 2025 】亮點新功能 【OptiStruct 2025~2025.1】技術新亮點 HyperWorks 2025新功能導覽與PhysicsAI應用展望 Altair 2023 HyperWorks新版本發佈會 HyperWorks 2025.1 新版本發佈
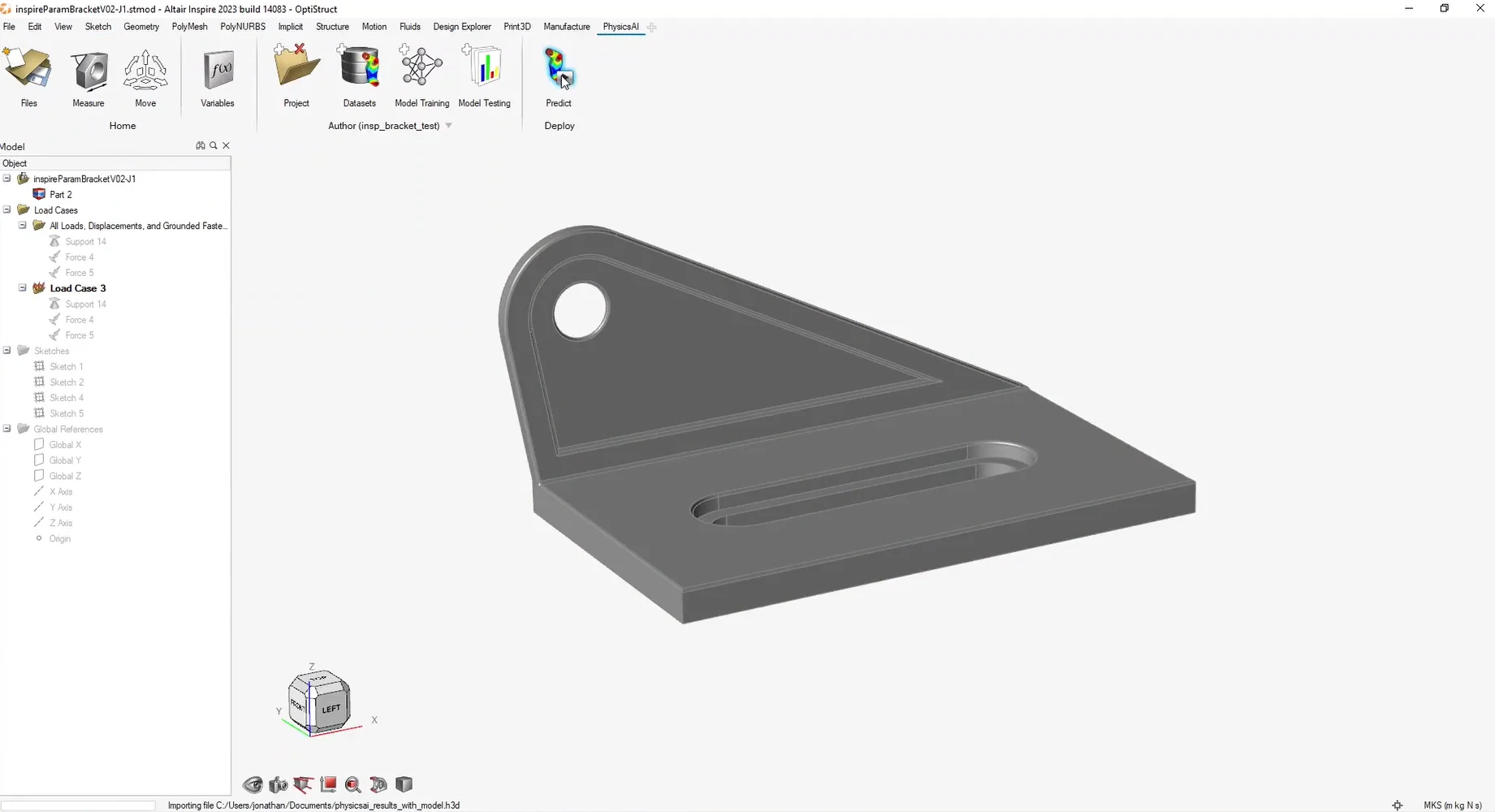
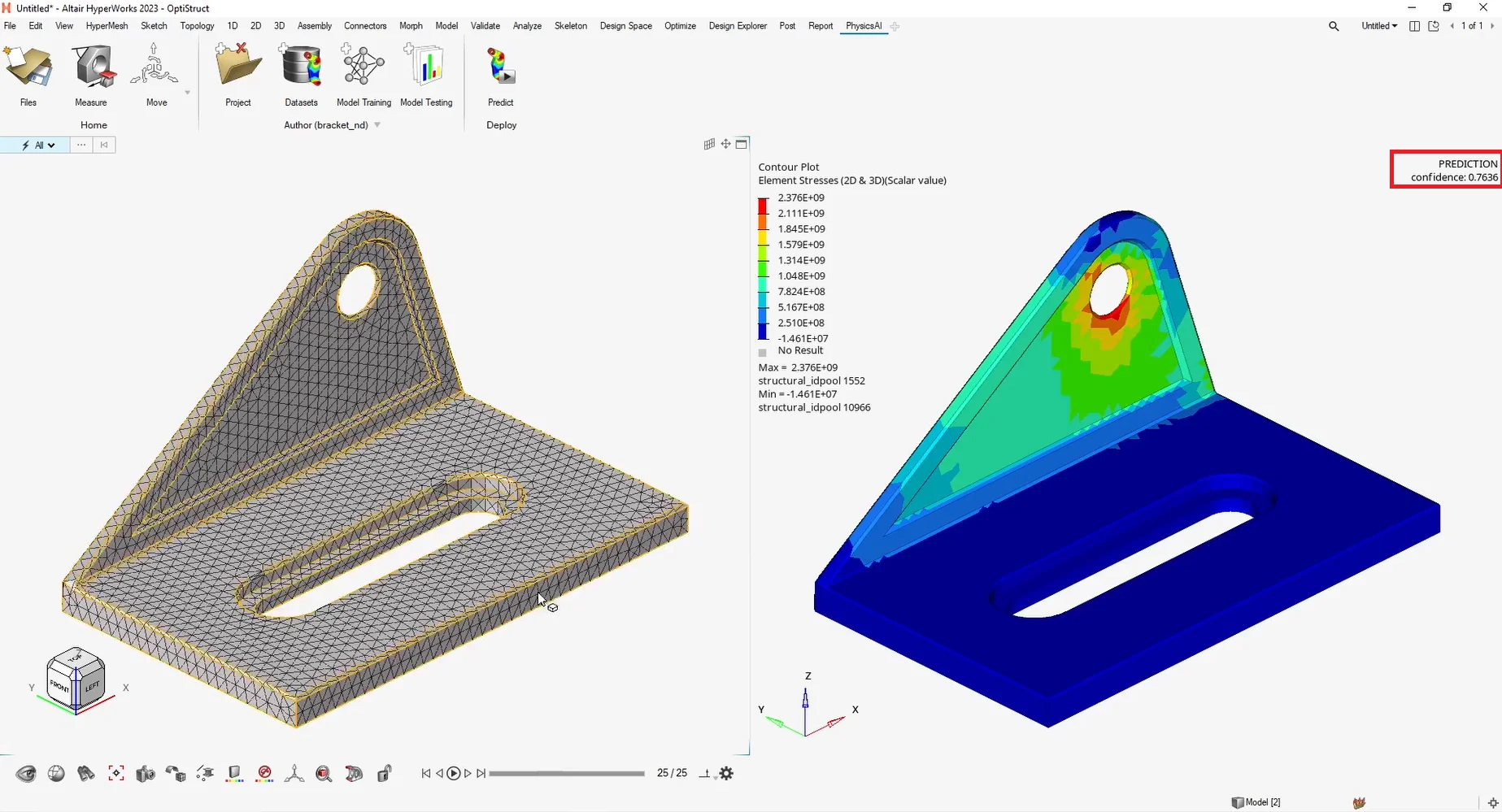
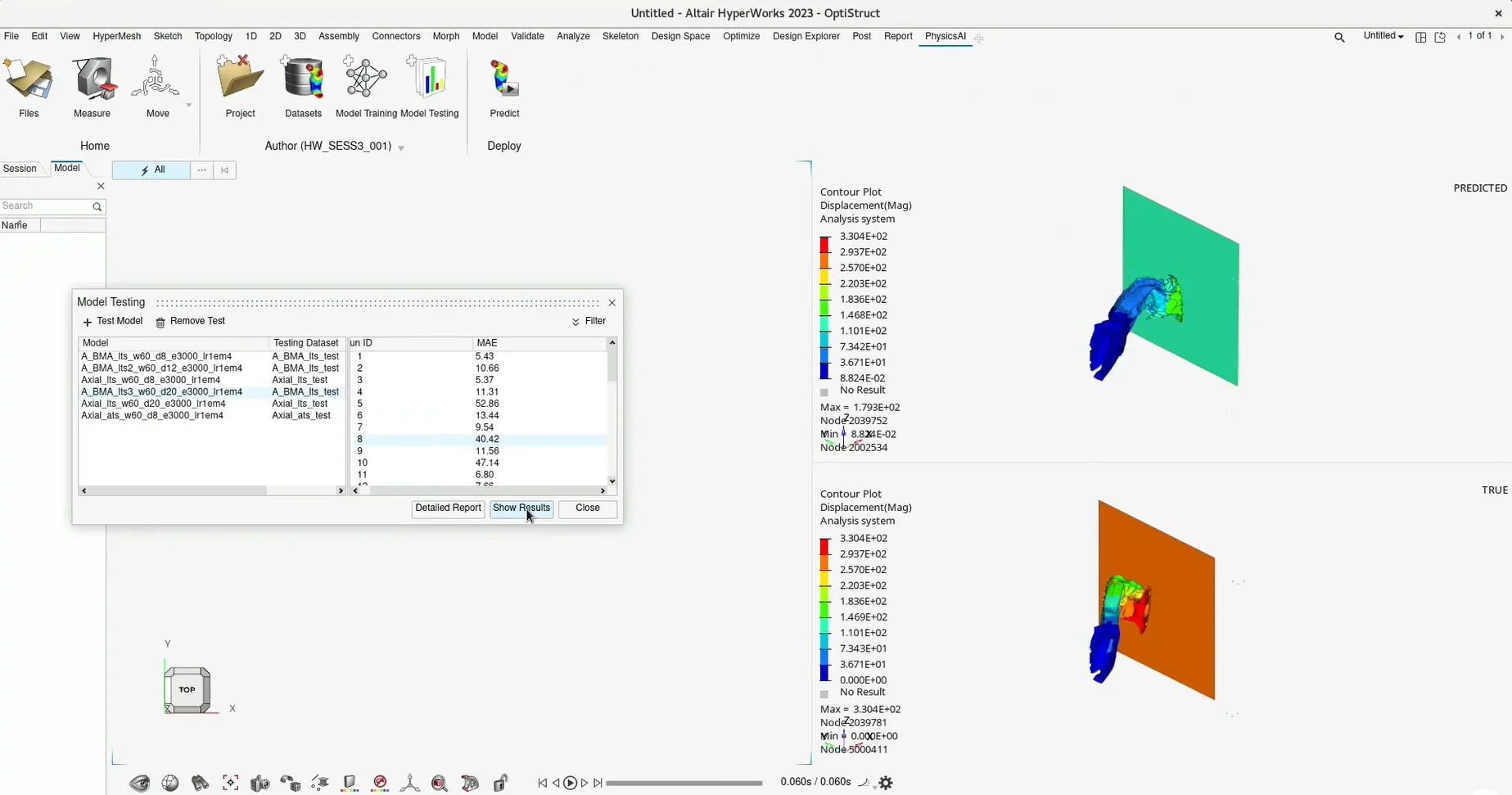
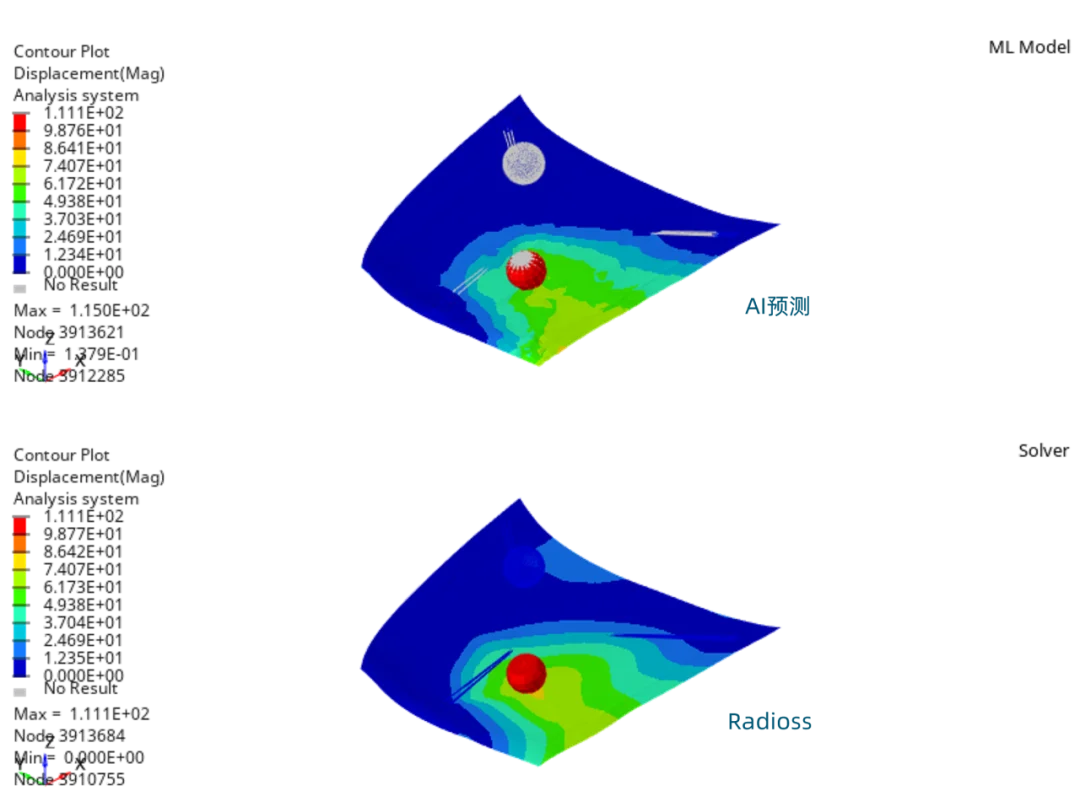
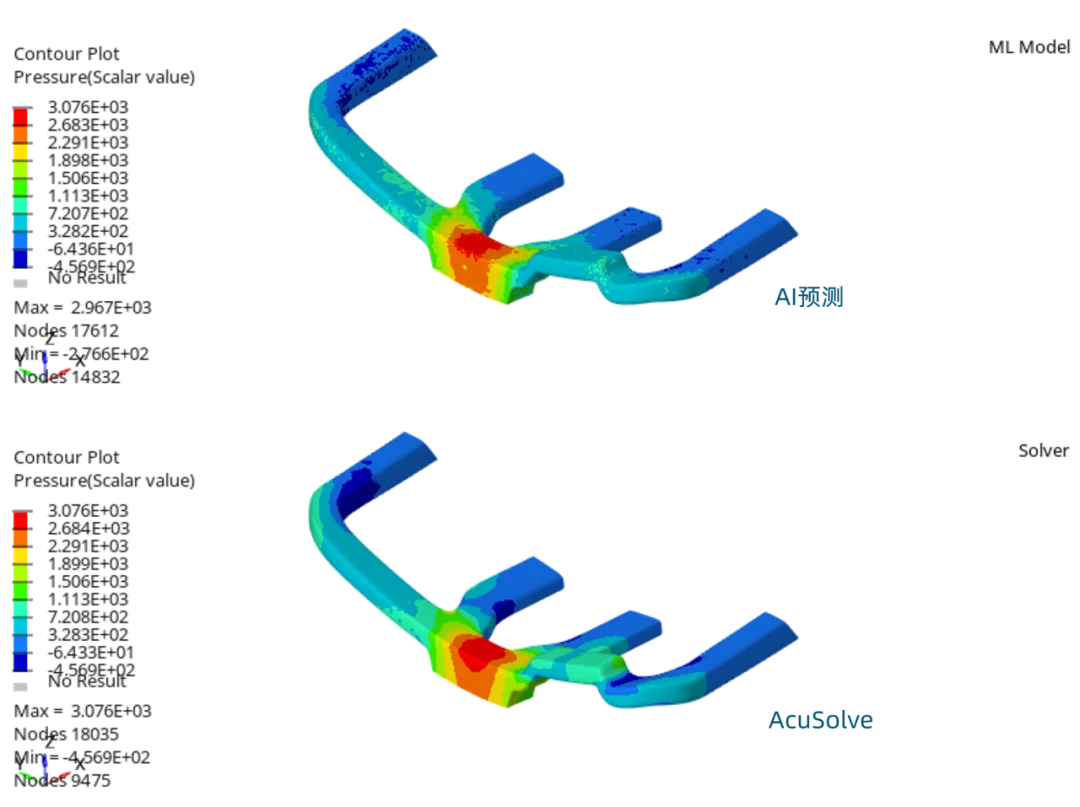
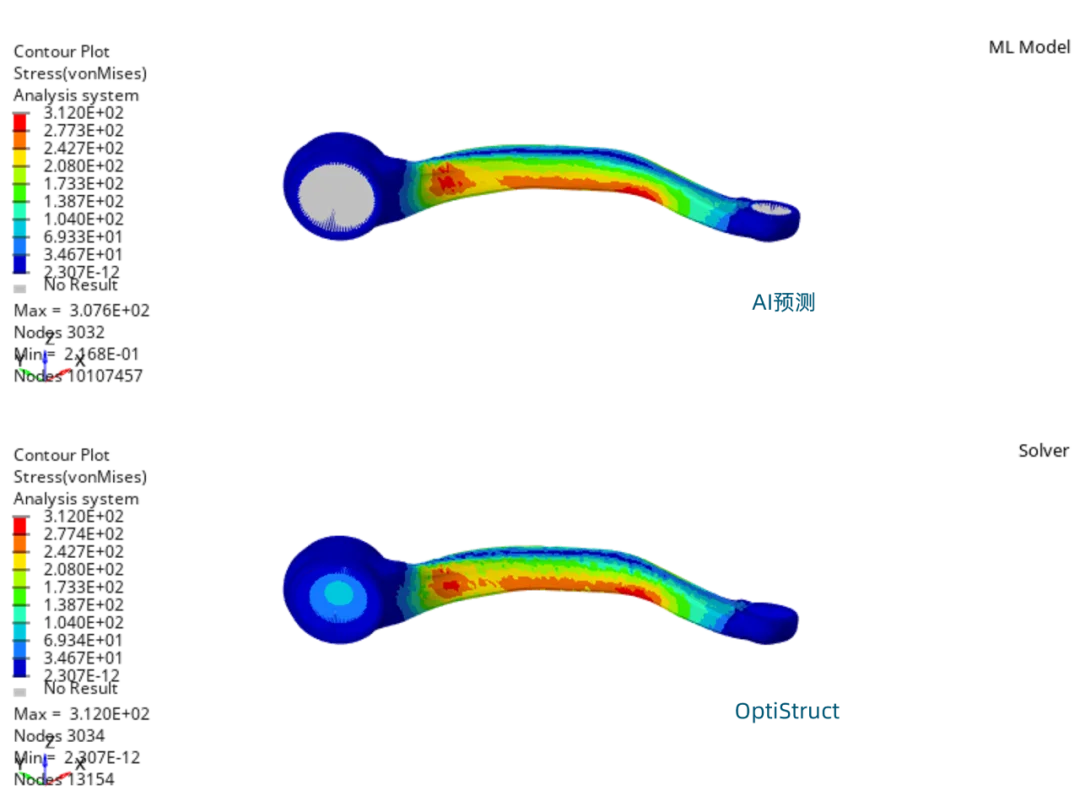
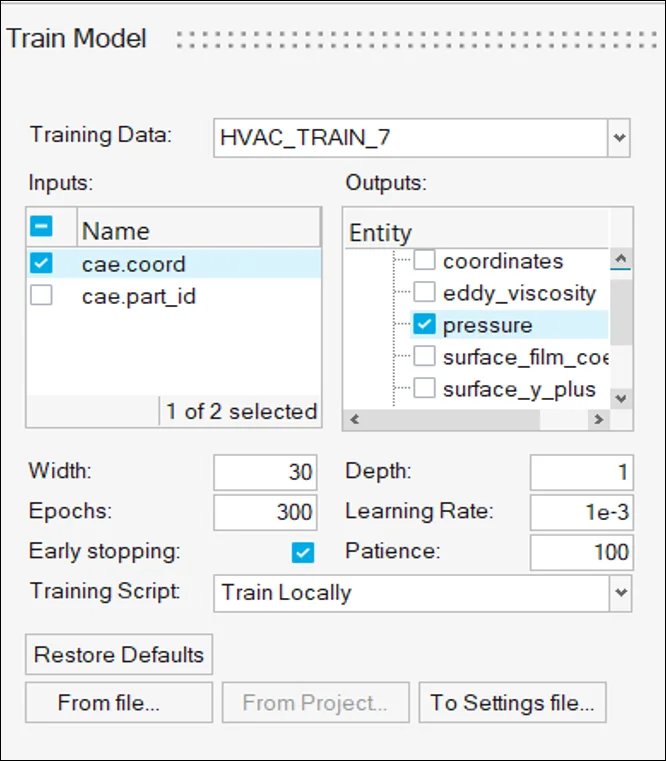
(安裝檔下載 & 硬體規格表) Read More...瑞其Youtube頻道【案例分享】SimLab|PCB建模與熱固耦合分析 【PSIM】認識PSIM的兩大應用:電力電子、馬達驅動控制 【AI大數據分析】系列 1:AI解密一次說給你聽 【AI大數據分析】系列 2 :馬達穩態性能預測 【AI大數據分析】系列 3 :馬達轉子溫度預測 【AI大數據分析】系列 4:傳統與AI預測模型之比較ROM與romAI 【AI大數據分析】系列 7:神奇的三維最佳化分析技術|Altair ExpertAI 【AI大數據分析】系列 8:以AI神奇的預測CAE結果|Altair PhysicsAI 【nanoFluidX 】Altair nanoFluidX CFD功能介紹 Read More... - 課程活動
- 最新消息
- 檔案下載
- 聯絡我們